
 Vivimos en la era del algoritmo. Muchas decisiones sobre nuestra actividad cotidiana (la cuota mensual que pagamos por un seguro médico, la selección de nuestro CV para una entrevista de trabajo, o la aceptación o rechazo de un crédito) no las toma ya un humano sino un modelo matemático. Y aunque, en teoría, esto debería conducir a una mayor igualdad ya que todo el mundo es juzgado en base a los mismos criterios, muchas veces ocurre lo contrario: los modelos son opacos, no están sujetos a regulación, con frecuencia están basados en hipótesis erróneas y refuerzan prácticas discriminatorias con los sectores más débiles de la sociedad. Esta marginación ha existido siempre, en la era digital simplemente se puede implementar de manera más eficiente e impersonal.
Vivimos en la era del algoritmo. Muchas decisiones sobre nuestra actividad cotidiana (la cuota mensual que pagamos por un seguro médico, la selección de nuestro CV para una entrevista de trabajo, o la aceptación o rechazo de un crédito) no las toma ya un humano sino un modelo matemático. Y aunque, en teoría, esto debería conducir a una mayor igualdad ya que todo el mundo es juzgado en base a los mismos criterios, muchas veces ocurre lo contrario: los modelos son opacos, no están sujetos a regulación, con frecuencia están basados en hipótesis erróneas y refuerzan prácticas discriminatorias con los sectores más débiles de la sociedad. Esta marginación ha existido siempre, en la era digital simplemente se puede implementar de manera más eficiente e impersonal.
Las empresas de seguros usan complejos modelos para fijar la prima de un seguro en función de las características del solicitante: una persona más mayor pagará más seguro de salud, y un conductor con poca experiencia más seguro de automóvil. En ambos casos, la prima mayor está justificada por un mayor riesgo, estimado sobre datos anteriores de personas con características similares. Pero los datos también muestran que las personas de renta más baja tienen mayor riesgo de enfermedad, ¿es lícito cobrarles una prima más alta? Para el modelo matemático, “edad” ó “nivel de renta” son variables predictoras que se tratan por igual para afinar y mejorar la predicción. Sin embargo, la ética obliga a poner límites a la eficiencia de dichos algoritmos, y condiciona por ejemplo qué variables son susceptibles de ser utilizadas. Con frecuencia los modelos utilizan proxys: variables supuestamente correlacionadas con otras de las que no disponen de información suficiente. Por ejemplo, usar el código postal como proxy del nivel de renta. El abuso de esta práctica produce modelos estadísticos cuyos datos de aprendizaje son poco más que ruido, y conducen a predicciones erróneas. Cómo dicen en la jerga: si metes basura, sacas basura.
 La cadena de tiendas Oxxo, perteneciente a Grupo Femsa, se encuentra actualmente “dominando” el mercado leonés, registrando mayor presencia que otras marcas.
La cadena de tiendas Oxxo, perteneciente a Grupo Femsa, se encuentra actualmente “dominando” el mercado leonés, registrando mayor presencia que otras marcas. Hoy en día nos encontramos en una época en la que la información se genera cada segundo de forma instantánea en todas las organizaciones y en cada uno de sus niveles, en el ámbito empresarial, tener a la mano la información necesaria pude significar una ganancia o una pérdida monetaria, a través de las últimas décadas, han aparecido y evolucionado los sistemas de planeación de los recursos empresariales para ayudar en este sector, mejor conocidos como ERP, son un tipo de software que permite a las empresas controlar la información que se genera en cada departamento y cada nivel de la misma.
Hoy en día nos encontramos en una época en la que la información se genera cada segundo de forma instantánea en todas las organizaciones y en cada uno de sus niveles, en el ámbito empresarial, tener a la mano la información necesaria pude significar una ganancia o una pérdida monetaria, a través de las últimas décadas, han aparecido y evolucionado los sistemas de planeación de los recursos empresariales para ayudar en este sector, mejor conocidos como ERP, son un tipo de software que permite a las empresas controlar la información que se genera en cada departamento y cada nivel de la misma.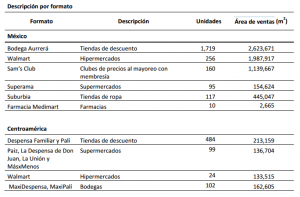 Walmart de México y Centroamérica informó que cuenta con un área de ventas de más de 6.3 millones de metros cuadrados en el mercado mexicano.
Walmart de México y Centroamérica informó que cuenta con un área de ventas de más de 6.3 millones de metros cuadrados en el mercado mexicano. Frente a movimientos en donde vemos una contracción de los puntos de venta en mercados como el estadounidense, los hábitos del consumidor consideran cada vez más el rol de las redes sociales y las plataformas digitales, sin embargo, es interesante ver la capacidad que por ejemplo tienen, las promociones digitales, cuando estas apoyan el desarrollo de publicidad online, como el gran motivante de compras en tienda, tras el estímulo que enfrentan los consumidores, motivados a acudir a las tiendas por anuncios móviles y una vez ahí, comparar precios usando su dispositivo móvil.
Frente a movimientos en donde vemos una contracción de los puntos de venta en mercados como el estadounidense, los hábitos del consumidor consideran cada vez más el rol de las redes sociales y las plataformas digitales, sin embargo, es interesante ver la capacidad que por ejemplo tienen, las promociones digitales, cuando estas apoyan el desarrollo de publicidad online, como el gran motivante de compras en tienda, tras el estímulo que enfrentan los consumidores, motivados a acudir a las tiendas por anuncios móviles y una vez ahí, comparar precios usando su dispositivo móvil. Las relaciones entre socios comerciales envuelven miles de documentos importantes tales como estimaciones, órdenes de compra y facturas que deben ser procesados manuales te de manera diaria.
Las relaciones entre socios comerciales envuelven miles de documentos importantes tales como estimaciones, órdenes de compra y facturas que deben ser procesados manuales te de manera diaria. América Latina enfrenta un escenario económico incierto y significativos cambios demográficos. Las ganancias extraordinarias derivadas del auge internacional de mas materias primas se desvanecen ante la desaceleración de los mercados . Para el 2017, el Banco Mundial prevé que la economía regional crezca un 1.8% y continúe expandiéndose en 2018, aunque ello dependerá en gran medida de la fortaleza de los mercados externos y la capacidad de abordar los desafíos macroeconómicos. Estos factores impactan directamente a las industrias y canales de compra, a los que se suma el surgimiento de una clase media más informada, cautelosa y exigente.
América Latina enfrenta un escenario económico incierto y significativos cambios demográficos. Las ganancias extraordinarias derivadas del auge internacional de mas materias primas se desvanecen ante la desaceleración de los mercados . Para el 2017, el Banco Mundial prevé que la economía regional crezca un 1.8% y continúe expandiéndose en 2018, aunque ello dependerá en gran medida de la fortaleza de los mercados externos y la capacidad de abordar los desafíos macroeconómicos. Estos factores impactan directamente a las industrias y canales de compra, a los que se suma el surgimiento de una clase media más informada, cautelosa y exigente. En muchas ocasiones queremos realizar una promoción de venta que incentive las ventas de manera rápida y que no perjudique a nuestro canal distribuidor o de venta, si bien podemos realizar una promoción donde por cada compra que nos realicen aplicamos un precio especial o un descuento, es decir una promoción por sell-in.
En muchas ocasiones queremos realizar una promoción de venta que incentive las ventas de manera rápida y que no perjudique a nuestro canal distribuidor o de venta, si bien podemos realizar una promoción donde por cada compra que nos realicen aplicamos un precio especial o un descuento, es decir una promoción por sell-in.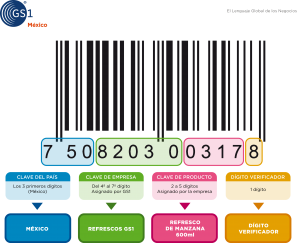 Información falsa sobre cómo identificar un producto elaborado por una empresa mexicana con sólo ver el Código de Barras, ha estado circulando desde hace más de un año a través de la aplicación de mensajería para teléfonos móviles whatsapp.
Información falsa sobre cómo identificar un producto elaborado por una empresa mexicana con sólo ver el Código de Barras, ha estado circulando desde hace más de un año a través de la aplicación de mensajería para teléfonos móviles whatsapp. Los proyectos de Big Data y analytics son en su inicio proyectos de tecnología, pero tiene que acabar siendo iniciativas que impacten de forma positiva en el negocio. A medida que esta estrategia se implanta en el día a día de las compañías va transformando la forma de trabajar de las unidades de negocio.
Los proyectos de Big Data y analytics son en su inicio proyectos de tecnología, pero tiene que acabar siendo iniciativas que impacten de forma positiva en el negocio. A medida que esta estrategia se implanta en el día a día de las compañías va transformando la forma de trabajar de las unidades de negocio.